Modern enterprise data migrations are still surprisingly manual.
Even with cloud-native tooling, engineers often spend significant time writing DDL scripts, mapping schemas manually, coordinating ingestion pipelines, handling orchestration dependencies, and maintaining infrastructure synchronization across cloud providers.
As datasets grow larger and architectures become increasingly distributed, this operational complexity compounds quickly.
We wanted to explore a different approach:
What if AI could operate as an autonomous infrastructure engineer inside a real analytics pipeline?
To test this idea, we built an end-to-end cross-cloud analytics platform that migrates StackOverflow data from Google BigQuery into ClickHouse using AWS as the intermediary cloud layer.
The system combines:
The most interesting part of the architecture is the infrastructure automation layer.
Instead of manually creating ClickHouse tables, queues, and materialized views, the pipeline dynamically asks Claude to inspect staged Parquet metadata and generate the required ClickHouse infrastructure automatically.
Claude then executes the generated DDL directly inside ClickHouse through an MCP-enabled workflow.
The final result is an autonomous analytics pipeline capable of:
The pipeline processed over 23 million StackOverflow records using a fully orchestrated workflow.
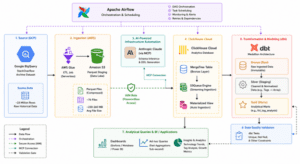
The overall architecture spans multiple execution environments and cloud providers.
At a high level, the system performs the following steps:
The complete workflow looks like this:
Google BigQuery (GCP)
↓
AWS Glue Extraction Job
↓
Amazon S3 (Parquet Staging)
↓
Apache Airflow Orchestration
↓
Claude + MCP Infrastructure Automation
↓
ClickHouse:
– MergeTree Table
– S3Queue Engine
– Materialized View
↓
dbt Medallion Models:
– Bronze
– Silver
– Gold
↓
Analytical Queries
The target analytics engine needed to support:
ClickHouse was selected because it combines high-performance OLAP execution with storage-engine optimizations specifically designed for analytical workloads at scale.
What differentiated ClickHouse for this project was not only raw query speed, but how its storage architecture minimizes scan overhead through sparse indexing, ORDER BY-driven data skipping, and columnar compression.
The project used the MergeTree engine as the primary analytical storage layer.
Unlike traditional OLTP databases, ClickHouse does not rely on row-level B-tree indexing for analytical workloads. Instead, MergeTree stores data in sorted parts and builds sparse primary indexes on the ORDER BY keys.
This allows ClickHouse to skip large portions of data during scans instead of reading every row.
As a result, table ordering strategies become extremely important because they directly influence data-skipping efficiency and analytical query performance.
This architecture was especially effective for workloads involving:
By physically organizing related data together on disk, ClickHouse minimized scan overhead and delivered sub-second analytical performance across millions of records.
ClickHouse stores each column independently in compressed format.
For analytical workloads like StackOverflow analysis — where queries often access only a subset of columns — this significantly reduces disk I/O and memory overhead compared to row-oriented systems.
This architecture was especially effective for:
One of the most powerful features used in the project was the S3Queue engine.
Instead of building polling services or custom ingestion workers, ClickHouse continuously monitored Amazon S3 for new Parquet objects and streamed them automatically into MergeTree tables through Materialized Views.
This eliminated the need for additional stream-processing infrastructure while dramatically simplifying ingestion logic.
Materialized Views connected the ingestion queue directly into the analytical landing tables.
As new Parquet files appeared inside S3, ClickHouse automatically pushed records into the destination MergeTree table.
This created a lightweight event-driven ingestion architecture without requiring Kafka, Spark Streaming, or external orchestration layers.
Another major reason for selecting ClickHouse was its strong cost-performance profile for analytical workloads.
To evaluate analytical execution efficiency, equivalent rolling-window analytical workloads were executed against the fct_tag_analysis mart in both ClickHouse and BigQuery using identical query logic and equivalent transformed datasets.
The benchmark workload included:
For this workload:
The ClickHouse query scanned approximately 192 MB of analytical data, while BigQuery consumed approximately 36.48 slot-seconds during distributed execution.
The benchmark demonstrated ClickHouse’s strong performance characteristics for interactive OLAP workloads involving:
Even at multi-million-row scale, ClickHouse consistently maintained highly responsive sub-second analytical query performance.
The source dataset originated inside Google BigQuery.
To move the data into AWS, the pipeline used AWS Glue as the extraction layer.
Airflow triggered a managed Glue job that:
The extracted data consisted of:
The final staging structure inside S3 looked like this:
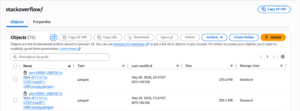
Using Parquet as the staging format significantly improved downstream ingestion efficiency because ClickHouse can read Parquet natively.
Apache Airflow coordinated the entire lifecycle of the platform.
The DAG contained six major stages:
The orchestration graph looked like this:
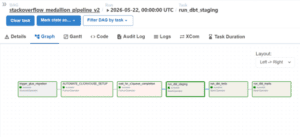
The pipeline was intentionally designed to be modular.
Each stage executes independently while still preserving deterministic execution order.
The DAG structure:
trigger_glue_migration >> automate_clickhouse_setup >> wait_for_ingest >> run_dbt_staging >> run_dbt_tests >> run_dbt_marts
This ensured that:
The DAG also included:
Adding dbt tests directly into the orchestration layer helped establish a controlled reliability boundary between ingestion and downstream analytics.
The most experimental component of the platform was the infrastructure automation layer.
Instead of manually writing ClickHouse DDL statements, the pipeline dynamically delegated infrastructure generation to Claude.
Airflow executed a PythonOperator that:
The orchestration logic looked like this:
response = client.messages.create(
model=”claude-opus-4-7″,
max_tokens=4000,
system=system_prompt,
messages=[{“role”: “user”, “content”: user_prompt}],
thinking={
“type”: “adaptive”
}
)
The prompt instructed Claude to:
The generated SQL was then executed programmatically:
statements = [s.strip() for s in sql_commands.split(‘;’) if s.strip()]
for statement in statements:
ch_client.command(statement)
This transformed Claude from a passive assistant into an active infrastructure automation layer.
Importantly, the system still maintained controlled execution boundaries.
Claude operated only within:
This approach avoided unrestricted autonomous execution while still removing repetitive infrastructure initialization work.
Improving AI-Generated Infrastructure with ClickHouse Agent Skills
One important observation during the project was that general-purpose LLMs can generate syntactically correct SQL while still missing workload-specific optimization patterns.
This became particularly visible during MergeTree schema generation and ORDER BY selection.
For example, the initial AI-generated schema proposed:
ORDER BY (id, creation_date)
While technically valid, this ordering strategy was not ideal for the analytical workload because downstream queries primarily filtered and aggregated by tags and time-series patterns rather than unique post IDs.
After reviewing the query access patterns, the schema was refined to:
ORDER BY (tag, creation_date)
which aligned significantly better with ClickHouse sparse primary indexing and data-skipping behavior.
This challenge closely aligns with the motivation behind ClickHouse Agent Skills, an open-source collection of ClickHouse-specific best practices designed for AI coding agents and LLM-driven infrastructure generation.
ClickHouse Agent Skills provide workload-aware guidance for:
These skills help AI agents move beyond generic SQL generation and produce infrastructure decisions that better reflect real ClickHouse analytical workloads.
In future iterations, integrating ClickHouse Agent Skills directly into the MCP orchestration layer could further improve autonomous schema generation by making workload-aware optimization part of the infrastructure automation process itself.
The generated infrastructure included:
Claude generated the final analytical landing table using MergeTree.
The schema was inferred dynamically from the Parquet metadata.
The pipeline then created an S3Queue ingestion layer pointing directly to the staged Parquet files.
A Materialized View connected the S3Queue engine to the MergeTree destination table.
This established continuous ingestion automatically.
The resulting ClickHouse structure looked like this:
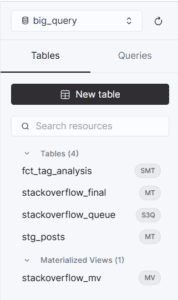
This included:
The infrastructure was generated dynamically without manually writing static DDL files.
Once ingestion completed, dbt transformed the raw records into structured analytical marts.
The project followed a Medallion-style architecture:
The Bronze layer stored raw ingested StackOverflow records exactly as they arrived from S3.
The Silver layer normalized and cleaned the records.
One major transformation involved parsing raw StackOverflow tags.
Original records looked like:
<python><pandas><aws>
The transformation layer converted these strings into analytical structures suitable for aggregation and filtering.
The main staging model was:
stg_posts
The Gold layer created analytical marts optimized for query workloads.
The final mart:
fct_tag_analysis
aggregated:
The dbt lineage graph looked like this:
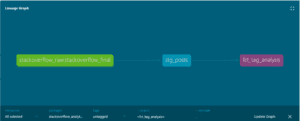
This provided a clean transformation dependency structure:
Raw Source → stg_posts → fct_tag_analysis
To improve transformation reliability, dbt tests were added directly into the orchestration workflow.
The stg_posts model validates that:
This helps detect:
before invalid data propagates into downstream analytical marts.
The validation layer establishes an important reliability boundary between ingestion and analytics.
The validation task was also integrated directly into the Airflow DAG:
run_dbt_tests = BashOperator(
task_id=’run_dbt_tests’,
bash_command=f’cd {DBT_PROJECT_DIR} && dbt test –select staging’,
)
This ensured that downstream marts only execute after transformation-level validation succeeds.
The transformation dependency structure remained:
Raw Source → stg_posts → fct_tag_analysis
One of the design goals of the platform was reducing static credential exposure.
Instead of embedding cloud credentials directly into ingestion logic, the platform used AWS IAM Role ARNs for controlled access.
This enabled ClickHouse to access S3 objects securely without exposing long-lived access keys.
Benefits included:
The S3 access layer was configured using inline IAM role authorization.
After the Gold marts were generated, ClickHouse handled several analytical query patterns efficiently.
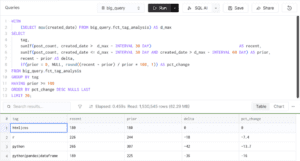
One of the queries aggregated the most active StackOverflow technology tags.
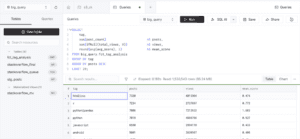
Despite scanning over 1.5 million transformed rows, the query completed in:
0.169 seconds
The pipeline also supported time-based analytical workloads.
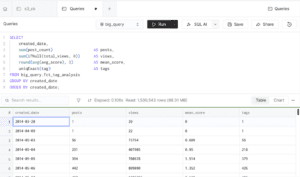
Window functions were used to compute rolling post activity trends.
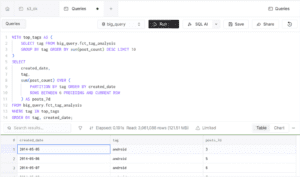
The query used:
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
to calculate rolling 7-day post metrics.
The Gold layer also enabled trend-detection analysis using interval-based comparisons.
These workloads demonstrated ClickHouse’s efficiency for:
Building the platform exposed several interesting engineering challenges.
Allowing AI to generate infrastructure dynamically can be powerful, but prompt boundaries are critical.
The execution layer worked reliably because:
Claude successfully generated the initial ClickHouse ingestion infrastructure dynamically from Parquet metadata.
However, optimizing analytical performance still required engineering validation of workload patterns.
The experience highlighted an important lesson:
AI can dramatically accelerate infrastructure initialization, but workload-aware optimization decisions still benefit from human engineering review.
The S3Queue engine eliminated a large amount of operational complexity.
Without it, the architecture would likely require:
The lineage tracking and modular transformation structure made the platform significantly easier to maintain.
The separation between:
kept the project organized even as query complexity increased.
Several areas could further extend the platform.
Future versions could automatically detect upstream schema drift and evolve ClickHouse tables dynamically.
The current architecture processes staged Parquet files.
A future iteration could integrate real-time CDC streams.
The orchestration stack could be containerized further for scalable distributed execution.
Adding tracing and telemetry would improve operational visibility across orchestration and ingestion layers.
This project explored what happens when AI is integrated directly into infrastructure orchestration instead of being limited to assistant-style interactions.
By combining:
it became possible to build a fully orchestrated analytics platform capable of:
The final platform successfully processed more than 23 million StackOverflow records while dynamically generating ingestion infrastructure during execution.
Most importantly, the project demonstrated that AI can operate effectively as a controlled infrastructure automation layer inside modern data engineering workflows.
Not by replacing engineers,
but by automating repetitive operational initialization tasks inside well-defined execution boundaries.
GitHub Repository:
https://github.com/AniketBShinde/stackoverflow-migration




